

The Belief Cost of Information: How Unaudited World Models Are Ruining Your Corporate Strategy
Every strategic memo, forecast, and competitive read leaving a Fortune 500 desk already passed through a Copilot, a Claude, or a GPT. Each of those systems is a world model. Nobody has audited the one they run on. Every decision made from them carries undisclosed risk, and until now, no one had a way to measure and offset it.
The Model You Didn't Install
For most of modern history, the information ecosystem ran as a two-body problem. Reality shaped the news, and the news shaped reality. The loop was messy and biased and human, but it was legible to the people whose decisions it drove.
A third body now sits inside that loop.
Large language models write the summaries, draft the memos, and produce the briefs that executives read before they decide. Those same models were trained on the corpus the old two-body system produced, absorbing every framing pattern and structural distortion baked into decades of coverage.
The loop has an amplifier in the middle now, and almost no one is auditing it.
Every strategic decision a Fortune 500 makes is already shaped by this third body. The market assessment, the competitor read, the regulatory forecast, the board memo. All of it moves through systems that inherit an unaudited world model from their information diet.
The reasoning looks flawless. The arguments land elegantly. The evidence sits crisply on the page.
The world model behind it was assembled from billions of English-language webpages, novels, and YouTube videos. Every biased, incorrect, uninformed, and warped point of view the public internet ever produced, mashed into one continuous prior the model treats as reality.
Hidden Failure.

In 2023, UnitedHealth, the fourth-largest company on the Fortune 500, deployed an AI tool called nH Predict to set discharge dates for elderly patients in post-acute care. The model had been trained on a corpus that under-represented patients with complex recoveries, but its outputs read fluent and confident, the kind of clean recommendations a case manager could action without question. Executives and operators deferred, and the discharges followed. A class-action lawsuit and a STAT News investigation later found the tool wrong roughly 90% of the time on appeal. Patients were pushed out of care before they were medically ready, and some did not recover.
That was a traditional, narrowly-trained machine learning model with bounded inputs and a single decision to make, and it still produced a 90% failure rate at scale. Now imagine the same pattern inside a large language model orders of magnitude more powerful, sitting inside every executive workflow on the planet, reasoning across every domain a Fortune 500 touches at once. The same disease, scaled across the entire decision surface of the corporation.
In March 2026, three frontier LLMs were asked whether Zelenskyy would wear a suit to a papal funeral, and all three answered yes at 91 to 95 percent confidence. The reasoning was airtight in the models' own terms, since heads of state wear formal attire to state funerals, yet every one of them was wrong. Zelenskyy has not worn a suit since February 24, 2022, and the wartime clothing is a deliberate political signal as integral to Ukraine's posture as any speech. The models had read every English-language story about Zelenskyy ever written and still missed the man behind the headlines.
The case is not a one-off. When we examined the models' own reasoning traces across 93,000 predictions, the same asymmetry was everywhere:

The corpus shaped the verbs. The verbs shaped the predictions. The predictions shaped the recommendations on the desk.
Somewhere right now, an executive is making a decision that will wipe out hundreds of billions in market value, vaporize millions of jobs, or set the conditions for the next war. The only voice in the room is a model fluent enough to sound right, patient enough to never disagree, and confident enough to be believed.
Right now, it is also telling him: You're a genius. You're absolutely right.
Why You Cannot See It Coming
The bias is upstream of the reasoning, and it is upstream of the model. Eric Ries put it at a recent closed-door long-term-investment gathering at Stanford as a law of how technology inherits whoever built it:
%20(1).jpg)
That argument runs through his forthcoming book, on why good organizations drift and how to keep them mission-aligned. The training corpus is the widest organization there is. The framings, the editorial blind spots, the values of every journalist, novelist, and forum poster who wrote it are now leaking through the model and onto the executive's desk - and the deeper the model reasons, the further that leakage carries.
Output quality is not evidence of input quality. An LLM that summarizes a market with elegant clarity, citing the right reports and framing the right tensions, can be reasoning from a world that does not match the one your company operates in. Nothing in the output tells you that.
What We Measured
To detect bias that lives upstream of any single output, we needed an instrument that compared what the model believed against something the world would later confirm. Prediction markets gave us that instrument: public, dated, financially incentivized, and resolved against reality. We used 111 Ukraine-related Polymarket events as the calibration reference, then varied the information the model could see while holding the model fixed.
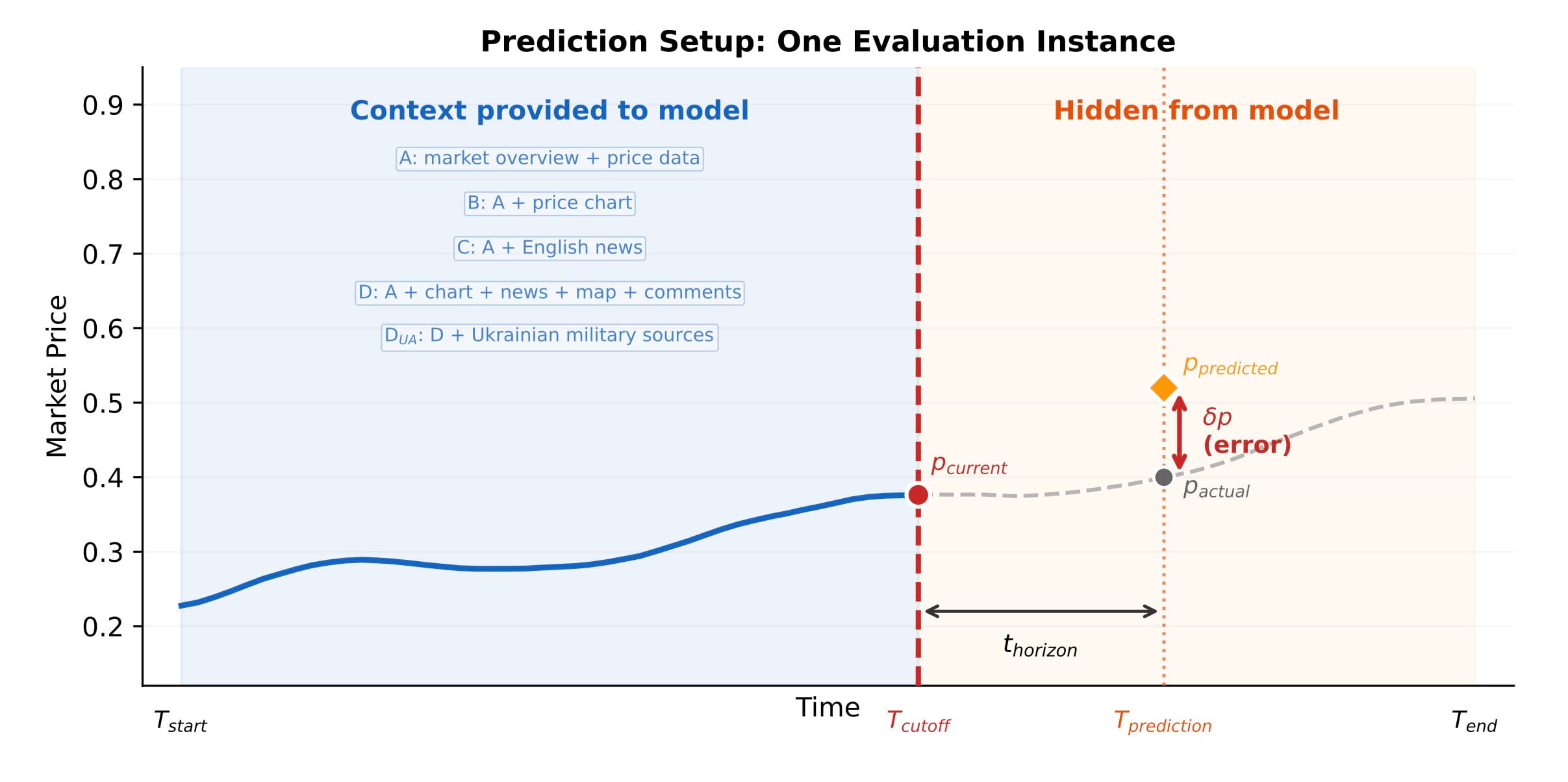
Across four frontier LLMs and 93,000 predictions, the central finding was unambiguous: adding mainstream English news degraded every clean model on territorial questions.
The model was wrong 64 to 72% of the time
Frontier LLMs were wrong when English news pushed them to predict Russian territorial capture. Across 4 models and 65 territorial markets, p < 10⁻⁶.
Even the contaminated control model - which had been trained on data extending past market resolution and already knew the actual outcomes - failed at almost exactly the same rate when English context pushed it toward capture.
Source diversification helped. When we supplemented the English ecosystem with Ukrainian military-analytical sources, the directional bias dropped across every architecture we tested.
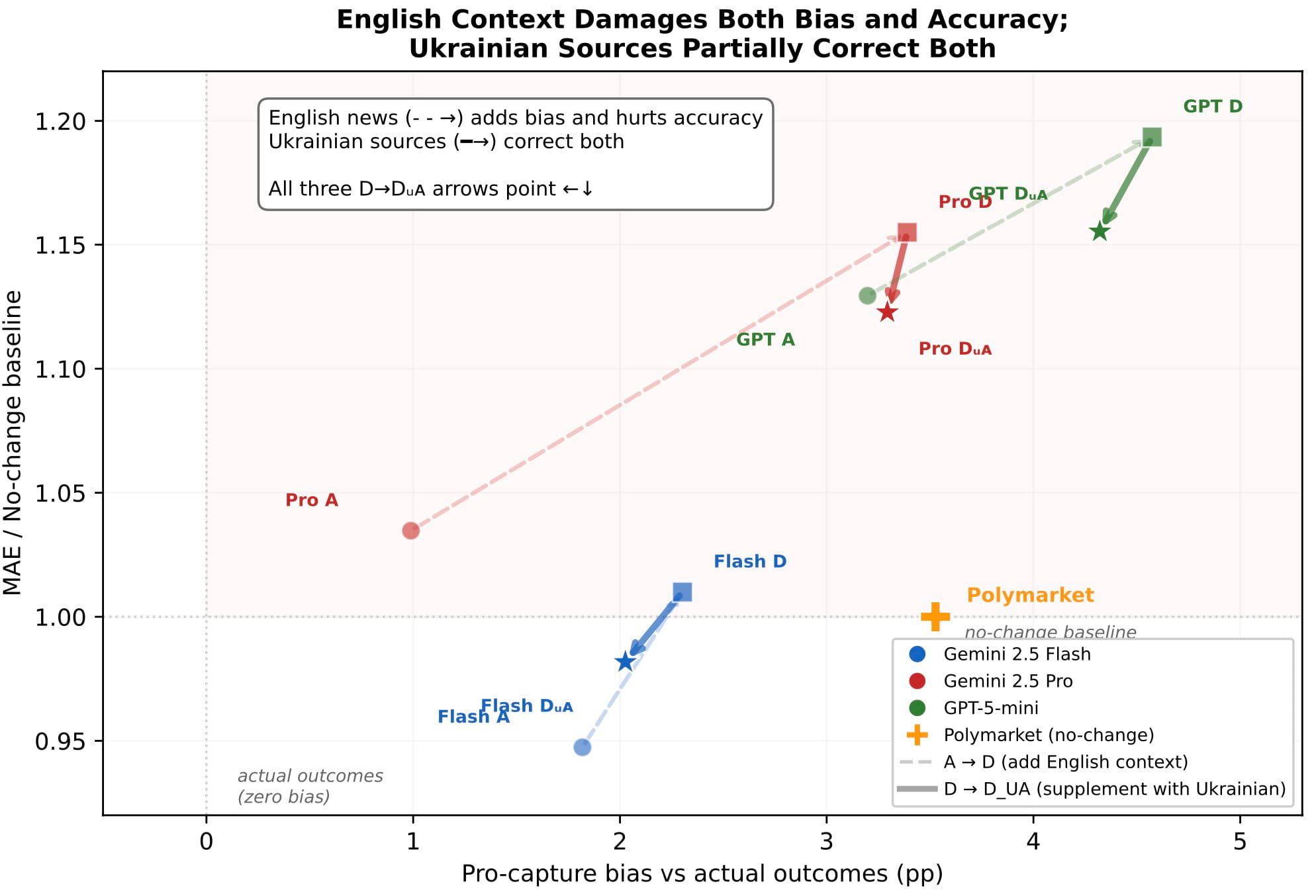
One finding deserves to be sat with on its own: deeper reasoning amplified the bias. The Pro model accumulated 5× more context damage than the Flash model trained on the same data. Eloquent reasoning carries the reader further into the wrong world.
Methodology and data. 111 Ukraine-related Polymarket events, January 2025 – January 2026. 65 territorial markets, 46 diplomatic. ~93,000 predictions across 5 information conditions × 4 frontier models (Gemini 2.5 Flash, Gemini 2.5 Pro, GPT-5-mini, and Gemini 3.1 Pro Preview as a contaminated control whose training data extends past market resolution dates). English news corpus: 16,457 articles across 2,217 domains. Full dataset and reasoning traces released openly and available on our repository.
The Death Spiral
Here is what concerns us most.
Secretly erroneous AI research steers secretly misguided executive decisions. Those decisions become the news. The news gets indexed as truth. Future models are trained on the indexed truth. The bias compounds.

Trust in any information layer degrades along with it.
This is not a problem that gets better on its own. It gets worse with every training cycle. The window to install the audit is now, before the third body becomes the only voice in the room.
What Changes When You Audit
The point of measuring is not to replace the AI on the desk. It is to give the human back the ability to disagree with it on something other than vibes.
An executive reading a Copilot-generated brief today is reading a confident summary from a world model they cannot inspect. The methodology sheet tells them how the prompt was constructed. It does not tell them which world the prompt was read against.
An audited world model surfaces the assumptions underneath the fluent output. It tells the human in the room which beliefs the AI is carrying and where those beliefs are likely to be wrong. It restores expertise to the position it lost the moment the AI started sounding more polished than the people who actually know the business.
At the same Stanford gathering, the CIO of one of the largest pension systems on earth offered the only test that matters: does this make us a better decision-maker? If you cannot answer that, you do not get to deploy it.
That is what Principle is for.
When I was asked on stage at that gathering for the most controversial thing about the work I do, my answer was that people think I'm selling tools to predict the future - but it's impossible to predict the future. Though, you can definitely design a better one. Action is not about accuracy. It's about being useful.
Principle does not help you predict the future. We help you design it.
The "ouroboros" of unaudited information doesn't have to be the terminal state of your corporate strategy. Principle is already helping global leaders - from governments to major energy and financial corporations alongside with helping reinvent "Big Four" accounting firms - helping audit their world models and reclaim strategic clarity. By transitioning from blind assumptions to verified foresight, these organizations are turning the "belief cost" into an ultimate competitive advantage.
Read the preprint:

Acknowledgements
We gratefully acknowledge our partners Amazon Web Services and DigitalOcean for the cloud compute credits and infrastructure that supported this work. Model inference, training, and evaluation pipelines were run on AWS (EC2 GPU instances).
About Principle
Principle is a world model for critical decision making. We simulate markets. Our CTO built user simulations for Google. Our lead scientist holds a Breakthrough Prize in physics. We've got 30 PhDs from top labs working on the world's largest simulator for decisions.
Artur Kiulian is CEO and founder of Principle.
References
Khandoga, M., Kostiuk, Y., Polishko, A., Filipchuk, Y., Kozlov, K., Zamriy, D., & Kiulian, A. (2026). Belief Propagation in LLM World Models: Measuring Strategic Information Bias with Prediction Markets. UNLP 2026 (preprint).
Karger, E., Bastani, H., Yueh-Han, C., Jacobs, Z., Halawi, D., Zhang, F., & Tetlock, P. E. (2025). ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities. International Conference on Learning Representations.
Xie, S. M., Raghunathan, A., Liang, P., & Ma, T. (2022). An Explanation of In-Context Learning as Implicit Bayesian Inference. International Conference on Learning Representations.
Nakov, P., An, J., Kwak, H., Mansurov, M. A., & Mansurov, M. (2024). A Survey on Predicting the Factuality and the Bias of News Media. Findings of the Association for Computational Linguistics: ACL 2024.
Ojala, M., Pantti, M., & Kangas, J. (2024). Framing the War in Ukraine: A Comparative Study of News Coverage. Journalism Studies.









